http-клиент выдает ошибку при скачивании больших файлов
-
Пытаюсь скачивать видео через http-клиент, примерно через минуту выдает ошибку "Не удалось получить страницу с помошью ХТТП клиента" (видимо, таймаут минута по умолчанию, установил таймаут больше - работает). Но ведь так не должно быть, раз получение контента продолжается. Вот если бы данные не поступали, тогда должна быть ошибка.
P.S. скачивание продолжается даже при остановке скрипта. И после выдачи ошибки "Не удалось получить страницу с помошью ХТТП клиента" http-клиент в этом потоке больше не может соединиться с другими адресами. Алгоритм примерно такой:While получение данных о файле с сервера начало блока "игнорирование ошибок" скачивание файла конец блока "игнорирование ошибок" EndПосле первой попытки скачивания и выдачи ошибки, шаг "получение данных о файле с сервера" уже не выполняется, выдавая ошибку соединения. Лечится установкой большего таймаута.
-
Вот если бы данные не поступали, тогда должна быть ошибка.
Это может привести к тому, что файл будет качаться очень долго и будут писать, что проект зависает, лучше уж пусть таймаут будет привязан только к полному времени загрузки.
P.S. скачивание продолжается даже при остановке скрипта.
Да, это баг, но не критический.
И после выдачи ошибки "Не удалось получить страницу с помошью ХТТП клиента" http-клиент в этом потоке больше не может соединиться с другими адресами.
Вот этого я не могу подтвердить. Я сделал тестовый проект, в котором видно, что хттп клиент способен выполнять следующие запросы, даже если предыдущий не удался.
-
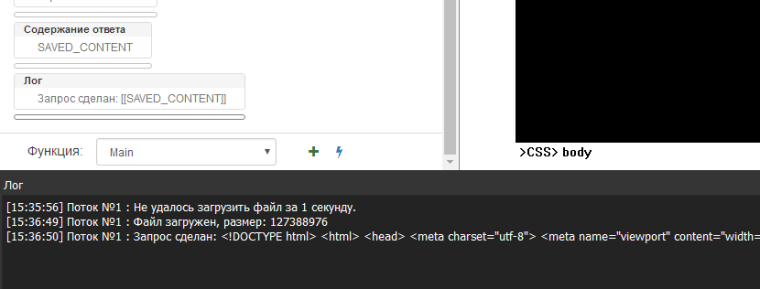
@support Если использовать дефолтный таймаут и игнор ошибок, то следующий запрос не выполняется
[18:17:04] Поток №1 : Не удалось загрузить файл за 1 секунду.
[18:18:05] Поток №1 : Файл загружен, размер: 127388976
[18:19:06] Поток №1 : Поток завершился с сообщением "Не удалось получить страницу http://bablosoft.com/ с помошью ХТТП клиента"
[18:19:06] Скрипт завершен корректно
0_1489756879431_1489755469517-httpcatch.xml
-
@blackhacker У меня результат другой
Что в режиме запуска, что в режиме записи.
Пробовал несколько раз.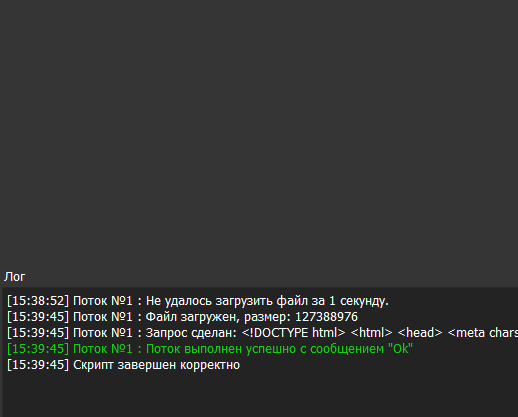
-
@support Может, я ошибаюсь, но ошибка возникает в том случае, когда файл еще грузится и последний запрос не успел выполниться до загрузки файла. Здесь видимо вышло так, что у меня канал меньше и забит, и поэтому файл не успевает докачаться. Когда проверил снова, то у меня тоже запрос был выполнен. Затем поставил таймаут второго запроса 5 секунд, и тогда последний запрос опять не был выполнен. Сейчас несколько раз проверил, ошибка повторяется. Алгоритм такой: запрос к большому файлу, файл не успевает докачаться по таймауту, но продолжает грузиться. Следующий запрос после запроса к файлу не выполняется. Но если файл успевает докачаться (даже после ошибки по таймауту) во время таймаута последнего запроса, то последний запрос выполняется.
0_1489758644952_1489755469517-httpcatch.xml
Но ошибка будет работать только в том случае, если у вас файл не успеет скачаться за полторы-две минуты.
-
@blackhacker Да, согласен ошибка, исправлю.

