Конструктор регулярных выражений
-
Хочу из исходного кода страницы сайта olx вытащить название обьявления и просмотры.
Вот пример кода с названием
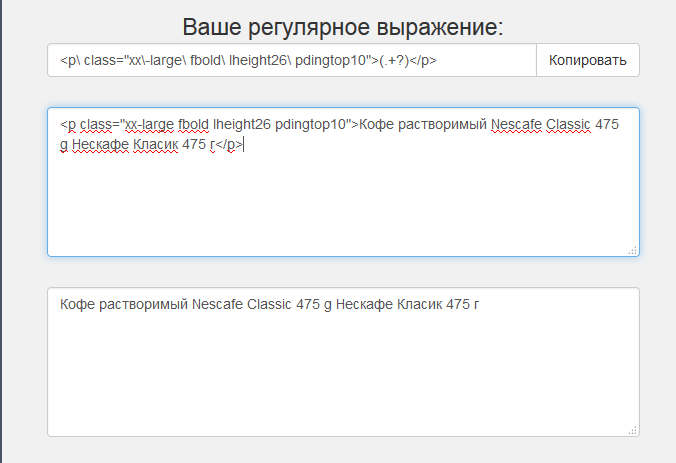
[<p class="xx-large fbold lheight26 pdingtop10">Кофе растворимый Nescafe Classic 475 g Нескафе Класик 475 г</p>]
Через конструктор создалась регулярка <p\ class="xx-large\ fbold\ lheight26\ pdingtop10">(.)</p> , но даже в самом конструкторе она не работает, в программе тоже.
Вот пример с просмотрами
Просмотры:<strong>70</strong>Регулярка - Просмотры:<strong>(.)</strong> тоже не работает
-
@DrPrime <p\ class="xx-large\ fbold\ lheight26\ pdingtop10">(.+?)</p>
там нужно выбрать
-
Спасибо, помогло
-
Опять столкнулся с проблемой
Большой текст, с хтмл разметкой, находится в
<p class="pding10 lheight20 large"> Рандомный текст тратата</p>
В тексте есть много пробелов. Регулярка, созданная способом выше, не работает
-
@DrPrime said in Конструктор регулярных выражений:
<p class="pding10 lheight20 large"> Рандомный текст тратата</p>
А если стандартными методами - получить текст
Или если вытаскиваете русский текст из общего кода html c разметкой - классами - спанами таблицами и тп - вытаскивайте регуляркой <p\ class="pding10\ lheight20\ large">(.+?)</p> - а потом через заменить строку очищайте текст, например - через регулярку удалось вытащить текст</td><td>текст1 - делаем замену строки [[полученный текст в переменную]] ->строка из -> </td><td> -> строка на - и указываем пробел, либо опять же регуляркой заменяем - любые латинские символы и символы из списка <>/
@DrPrime дайте кусок кода для тренировки
-
@Turutur
<p class="pding10 lheight20 large">
Доставка по ВСІЙ Україні<br>
<br>
Сорт - Королева Анна<br>- високоврожайний<br>
- середньоранній<br>
- столовий<br>
- стійкий проти вірусів<br>
<br>
! Власне виробництво за німецькою технологією вирощування насіннєвої картоплі<br>
! Налагоджена співпраця з провідними селекційними компаніями Європи -- "Solana" та "Den Hartigh" --<br>
<br>
Пропонуємо також багато інших сортів.<br>
Телефонуйте - ДОПОМОЖЕМО обрати оптимальний сорт для ВАШИХ потреб. </p>
-
@DrPrime (?<=<p\ class="pding10\ lheight20\ large">)[\w\W]*(?=</p>)
ну а дальше чистить строку - "заменить строку" из - на
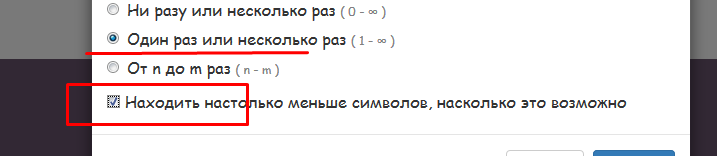
@support - пожалуйста доработайте конструктор регулярок - самое короткое совпадение есть - а переноса строки нет
-
@Turutur что то все равно в бас не работает
-
@DrPrime - вот так работает <p\ class="pding10\ lheight20\ large">([\w\W]*)</p>
-
@DrPrime html гораздо удобнее парсить по xpath. В проекте xpath от меня и регулярка, которую предложил @Turutur
-
@Turutur А как почистить. Нужно убрать двойные лишние пробелы и переносы строки. Пробовал /r/n заменять на пустоту, не получается
-
@support - да по xpath - хорошо, если соответствует определенному классу - если не разбито по коду - через регулярку немного сложнее - требуется дополнительная обработка!!!! Кстати о ней!!! - немного не согласованны действия в BAS для обработки текстов - например - невозможно обработать список действием заменить строку - пока не объеденишь список в строку - очень сложно для простых юзеров как мы - я временами не догоняю как так - вот сейчас на этом примере - я регуляркой <p\ class="pding10\ lheight20\ large">([\w\W])</p>*
вытаскиваю текст
[
"
Доставка по ВСІЙ Україні<br>
<br>
Сорт - Королева Анна<br>високоврожайний<br>
середньоранній<br>
столовий<br>
стійкий проти вірусів<br>
<br>
! Власне виробництво за німецькою технологією вирощування насіннєвої картоплі<br>
! Налагоджена співпраця з провідними селекційними компаніями Європи -- "Solana" та "Den Hartigh" --<br>
<br>
Пропонуємо також багато інших сортів.<br>
Телефонуйте - ДОПОМОЖЕМО обрати оптимальний сорт для ВАШИХ потреб. "
],который автоматически записывается в переменную как список
а дальше пока я его не объеденю в строку - я не могу ничего в нем найти и заменить - а это ведь не правильно! - @support - сделайте пожалуйста возможность обработки списков и вообще любых текстов - потому что проблемы возникали и с удалением дубликатов - или разъясните как устроено - да и если не сложно в действиях заменить элементарные подсказки типа убрать переносы строк - убрать лишние проелы и так далее.... ну вот опять меня понесло - просто реально такую ситуцию обсасывал несколько дней - и щас т о же самое"$.*^" - пробовал заменить на "\s" - не работает
"\n\r" - на "" - не работает, как в принципе и другие варианты -а по вашему примеру - получили xpash - просто в переменную - не в список - но с ней опять же ничего не получается сделать - в чем загвоздка - уже просто интересно???
-
@DrPrime - у меня пока только получилось объеденить в строку и убрать все пробелы)
-
а дальше пока я его не объеденю в строку - я не могу ничего в нем найти и заменить - а это ведь не правильно!
Вы же понимаете, что со списком работает действие foreach и позволяет обрабатывать каждый элемент отдельно?
проблемы возникали и с удалением дубликатов
Какие?
или разъясните как устроено
Функция удаление дубликатов удаляет повторы из списка. Как вы ожидаете что она будет работать.
убрать переносы строк
убрать переносы строк из строки можно обычным действием заменить. Я уже показывал в другой ветке форума как это делать.
Убрать переносы строк из каждого элемента списка можно пройдясь по нему действием Foreach
и щас т о же самое
А что случилось?
"\n\r" - на "" - не работает, как в принципе и другие варианты -
Странно, у меня работает, пришлите проект.
по вашему примеру - получили xpash - просто в переменную - не в список - но с ней опять же ничего не получается сделать - в чем загвоздка
Что не получается?
-
@support said in Конструктор регулярных выражений:
Какие?
или разъясните как устроено
Функция удаление дубликатов удаляет повторы из списка. Как вы ожидаете что она будет работать.
вот проект 0_1475916493058_test_.xml - объясните что не так - а то походу сам не разберусь
@support said in Конструктор регулярных выражений:
Странно, у меня работает, пришлите проект.
по вашему примеру - получили xpash - просто в переменную - не в список - но с ней опять же ничего не получается сделать - в чем загвоздка
Что не получается?
вот второй пример\ы 0_1475918159724_parserssclass.xml - там я два примера использовал - первый "\n\r" - на "" - не проверил - так как вводит в заблуждение отображения текста полученного xpath - в инспекторе переменных он выглядит как форматированный текст с переносом строк, пустыми строками - но при записи в файл понимаешь, что это всего лишь строка с лишними пробелами, поэтому использую второй вариант
"\s{2,}" на "\s" - то же нет результата.@support - я не пытаюсь обозначить свою точку зрения - я реально ищу помощи - хочу разобраться - и такие простые вещи вводят в ступор = вроде все очевидно - указал данные для фильтрации дублей - дубли удалились - ан нет), попытался убрать пробелы - не тут то было))) - объясните пожалуйста
-
вот проект 0_1475916493058_test_.xml - объясните что не так - а то походу сам не разберусь
На момент когда выполняется действие удалить дубликаты в списке есть 1 элемент. Соответственно это действие не имеет смысла
вот второй пример\ы 0_1475918159724_parserssclass.xml
вместо
"\n\r"нужно использовать"\r\n"и"\n"иногда символы окончания строки бывают такими, иногда такими.
Второе действие не работает, так как "заменить" не работает с регулярками.объясните пожалуйста
-
@support said in Конструктор регулярных выражений:
На момент когда выполняется действие удалить дубликаты в списке есть 1 элемент. Соответственно это действие не имеет смысла
@support - действие не имеет смысла для программного кода - но имеет смысл для меня - в том то и дело - как реализовать так чтобы и программа понимала, что нужно удалить повторяющиеся значения - это нужно в том случае, если я не использую Фореач - а не использую я его потому, что это долгий и нудный процесс - например мне нужно спарсить сначала группы в одноклассниках по целевым запросам - их 100 - а потом спарсить с них пользователей - по 100 с каждой группы - а это 100 загрузок страниц - плюс еще и фореач - по 100 по каждому элементу - а это 10000 действий имеющих временные затраты - ИЛИ я это сделаю через xpath или регуляркой, а затем удялю дубли - скорость выполнения возрастает в разы!!! Вот для чего все это нужно..
Если это один элемент не имеющий смысла- как его разделить на множество отдельных и отфильтровать?
-
@support said in Конструктор регулярных выражений:
Второе действие не работает, так как "заменить" не работает с регулярками.
подскажите вариант решения - удаления лишних пробелов - пробел вначале строки, пробел в конце строки, 2 и более пробелов идущих подряд.
-
действие не имеет смысла для программного кода - но имеет смысл для меня
Есть действия, которые выполняются на списках, есть действия которые выполняются на строках. С этим ничего не поделаешь.
как реализовать так чтобы и программа понимала, что нужно удалить повторяющиеся значения
http://community.bablosoft.com/uploads/files/1475927491987-removeduplicates.xml
Фореач - а не использую я его потому, что это долгий и нудный процесс - например мне нужно спарсить сначала группы в одноклассниках по целевым запросам - их 100 - а потом спарсить с них пользователей - по 100 с каждой группы - а это 100 загрузок страниц - плюс еще и фореач - по 100 по каждому элементу - а это 10000 действий имеющих временные затраты - ИЛИ я это сделаю через xpath или регуляркой, а затем удялю дубли - скорость выполнения возрастает в разы!!! Вот для чего все это нужно..
Я про цикл по элементам списка, а не по элементам на странице. Он не требует существенных временных затрат.
подскажите вариант решения - удаления лишних пробелов - пробел вначале строки, пробел в конце строки, 2 и более пробелов идущих подряд.
Пожалуйста
-
@support Спасибо, с пробелами помогло. А как еще убрать переносы строк? Вот пример с моим текстом 0_1475939323425_1475935789915-removespaces.xml
-
@support said in Конструктор регулярных выражений:
Пожалуйста
0_1475935789462_removespaces.xmlспасибо Большое - что даете примеры и только не понятно - как бы так логически воспринимать программу - типа интуитивно понятный интерфейс. В примере с 0_1475935789462_removespaces.xml - действие "удалить по значению" - ни содержит в себе ничего!!! - даже пустых пробелов нет, но все же как то удаляет повторяющиеся пробелы - вернее пустые значения спарсеного списка, тогда не понятно почему он не удаляет вообще все пробелы в тексте???? @support пожалуйста поймите, что я хочу до Вас донести!!!
Поставьте себя на наше место!!! - Какими логическими умозаключениями я прийду к этим действиям самостоятельно??? Никакими!!! Пока Вы не поможете! Или я случайно так не сделаю!
@support я же просто предлагаю давать готовые решения в BAS в виде действий! - Ведь Вас же не затруднит, например добавить в BAS всего пару действий 1 - удалить пустые строки!!! 2-е удалить повторяющиеся пробелы или как -то так, то есть сделать то, что Вы итак делаете! Ведь согласитесь, для Вас это будет гораздо быстрее чем часами переписываться с нами. Это я упрямый и пытаюсь разобраться - другие просто уйдут ничего не поняв.


